
The 2017 Hands in the Million Challenge on 3D Hand Pose Estimation

Abstract
We present the 2017 Hands in the Million Challenge, a public competition designed for the evaluation of the task of 3D hand pose estimation. The goal of this challenge is to assess how far is the state of the art in terms of solving the problem of 3D hand pose estimation as well as detect major failure and strength modes of both systems and evaluation metrics that can help to identify future research directions. The challenge follows up the recent publication of BigHand2.2M and First-Person Hand Action datasets, which have been designed to exhaustively cover multiple hand, viewpoint, hand articulation, and occlusion. The challenge consists of a standardized dataset, an evaluation protocol for two different tasks, and a public competition. In this document we describe the different aspects of the challenge and, jointly with the results of the participants, it will be presented at the 3rd International Workshop on Observing and Understanding Hands in Action, HANDS 2017, with ICCV 2017.
Note: in this page we include all the information needed for participation and we will update it periodically. For more detailed information, please check the following document.
NEW! (12/2019): We have released test annotations and also the full BigHand2.2M dataset. See below for instructions.
NEW! (07/2019): We are organizing the HANDS 2019 challenge!
NEW! (07/2019): Codalab, the service hosting our competition, suffered a major crash of their system and some late submissions were lost. You may need to re-register and re-enter your last submission.
NEW!: Our paper analyzing the results of the challenge has been accepted to CVPR 2018 as a spotlight presentation!
NEW!: Awards to the best performing teams will be presented during the workshop!
Challenge tasks
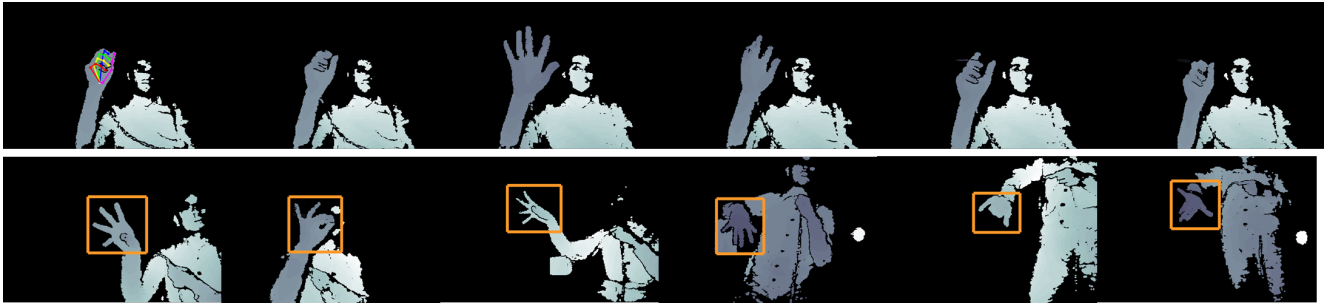
We present the two tasks evaluated in this challenge: 3D hand pose tracking and 3D hand pose estimation.
- 3D hand pose tracking: This task is performed mainly on sequences of 2700-3300 frames each and a few short sequences of 150 frames each. Given the full hand pose annotation in the first frame, the system should be able to track the 21 joints’ 3D locations in the whole sequence
- 3D hand pose estimation: This task is performed on individual images, each image is randomly selected from a sequence and the bounding box of the hand area is provided. The system should be able to predict the 21 joints’ 3D locations for each image.
- Hand-object interaction 3D hand pose estimation: we provide 2965 frames of fully annotated hand interacting with different objects (e.g, juice bottle, salt bottle, knife, milk bottle, soda can, etc.) All the images are captured in egocentric setting. The system should be able to predict the 21 joints’ 3D locations for each image.
Dataset details
The dataset is created by sampling images and sequences from BigHand2.2M [2] and First-Person Hand Action (FHAD) [3] datasets. Both datasets are fully annotated (21-joints) using an automatic annotating system with six 6D magnetic sensors and inverse kinematics. The depth images are captured with the latest Intel RealSense SR300 camera at 640 × 480-pixel resolution. For more details about dataset construction check the related document.
Training data
The training set is built entirely by sampling the schemed and egocentric poses from BigHand2.2M dataset. The training data is randomly shuffled to remove temporal information. 21 joints ground truth annotation is provided. More details can be found in the table below.
Test data
The test data consists of three components (for each task):
- Random hand poses of ten subjects (five seen in the training data and five unseen).
- Egocentric object-free hand poses (five seen in the training data and five unseen)
- Egocentric with object hand poses (from the FHAD dataset).
- 3D hand pose tracking: the test data is segmented into small segments of consecutive frames with 21 joints ground truth annotations provided only for the initial frame. In this task, there are 99 segments from BigHand2.2M dataset, each has 2700-3300 consecutive frames, and a few short sequences of 150 frames per each from FHAD.
- 3D hand pose estimation: the test data is randomly shuffled to remove motion information, with hand bounding box provided for each frame. In total, there are around 296K frames of test data in this task.
- Hand-object interaction 3D hand pose estimation: We have randomly shuffled the frames’ order, and provided the bounding box of the hand. When two hands appear in a frame, we only consider the right hand. In total, there are 2965 frames involving different objects in different scenarios.
In the following table we show in detail the numbers of the dataset:
| # of | Scenarios | Training | Test: Tracking | Test: Pose estimation |
|---|---|---|---|---|
| subjects | 3rd view ego view action | 5 5 0 | 10 10 - | 10 10 2 |
| seen subjects | 3rd view ego view action | 5 5 0 | 5 5 - | 5 5 2 |
| unseen subjects | 3rd view ego view action | 0 0 0 | 5 5 - | 5 5 0 |
| sequences | 3rd view ego view action | 30 5 0 | 67 32 - | 67 33 - |
| frames | 3rd view ego view action | 873,000 83,000 0 | 187,000 109,000 - | 187,000 109,000 2965 |
Participation
The submission deadline is the 15th September 2017 1st October 2017. To have your method evaluated, run it on all of the test sequences and submit the results in the same format as that of the annotation training data.
Only one submission per day per team is allowed. We will try to update the website regularly with the leaderboard for different metrics. Only the best result of each team will be posted in this website.Not valid anymore as we decided to switch to an automatic system for evaluation (CodaLab website for the challenge)- For each submission, you must keep the parameters of your method constant across all testing data.
- If you want your results to be included in a publication about the challenge, a documentation of results is required. Without the documentation, your results will be listed on the website but not included in the publication. The documentation must include an overview of the method with a related publication if it is published.
- For training, you can use the provided training images. You can also obtain extra training images by augmenting the existing images, e.g., by in-plane rotating the training images. Augmentations Any external data (other datasets, synthetic data, etc.) is not allowed. Any data augmentation technique must be reported in the documentation.
Annotation and results format
The annotation file is a text file, each line is the annotation for a frame and is formated as the following:
- Each line has 64 items, the first item is the frame name.
- The rest 63 items are [x y z] values of the 21 joints in real-world coordinates (mm)
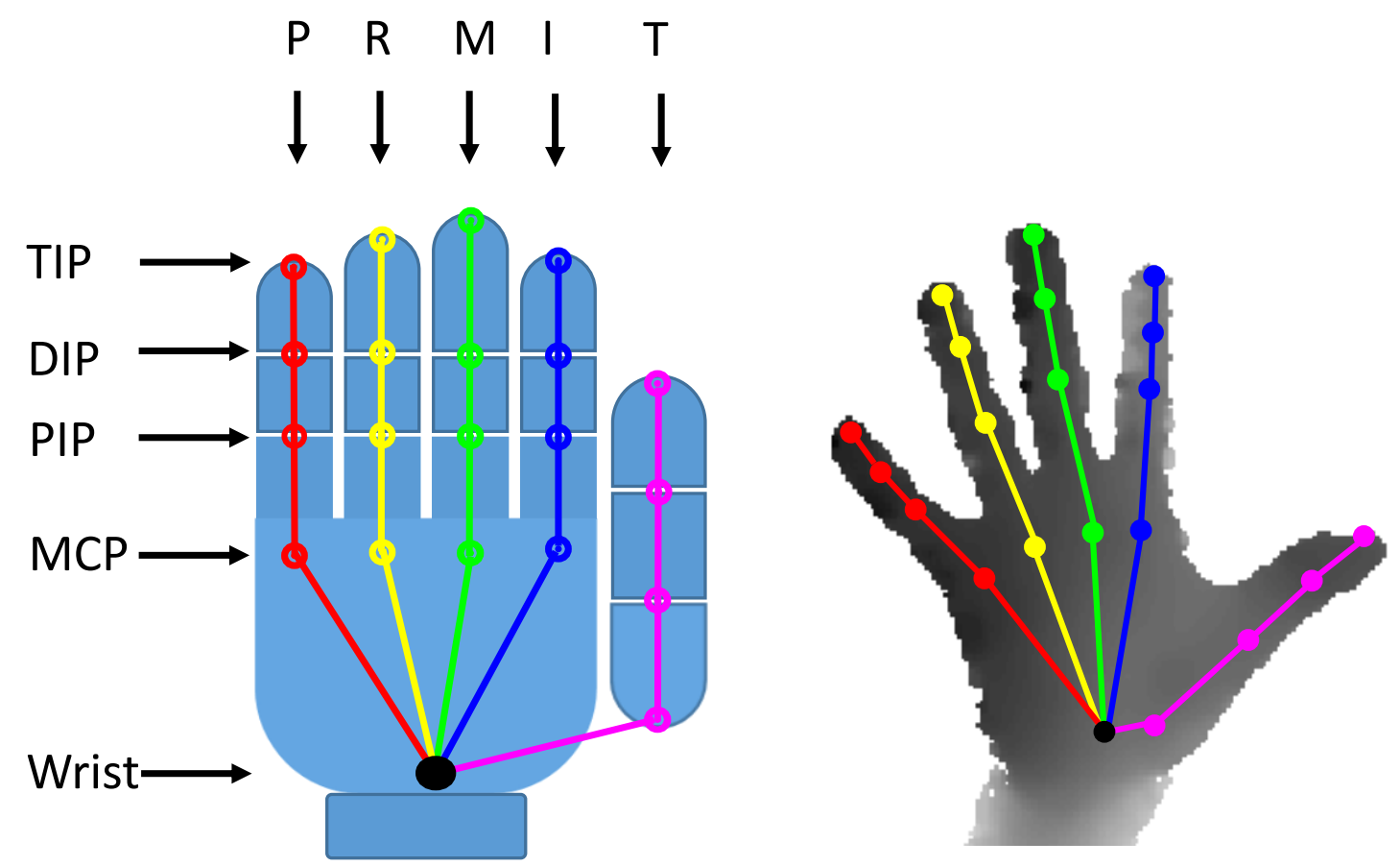
The joints are ordered in this way: [Wrist, TMCP, IMCP, MMCP, RMCP, PMCP, TPIP, TDIP, TTIP, IPIP, IDIP, ITIP, MPIP, MDIP, MTIP, RPIP, RDIP, RTIP, PPIP, PDIP, PTIP], where ’T’, ’I’, ’M’, ’R’, ’P’ denote ’Thumb’, ’Index’, ’Middle’, ’Ring’, ’Pinky’ fingers. ’MCP’, ’PIP’, ’DIP’, ’TIP’ as in the following Figure:
Evaluation
The hand pose results will be evaluated using different error metrics. The aim of this evaluation is to identify what success and failure modes of different methodologies. We will use both standard error metrics and new proposed metrics that we believe will provide further insights into the performance of evaluated methodologies. For each submission, we will provide the results for each error metric and a overall score combining all of them, which will be used to decide the challenge winner and the order in the leaderboard. The evaluation metrics are mentioned next. For more details check the related document.
Standard error metrics
- The mean error for all joints for each frame and average across all testing frames.
- The ratio of joints within a certain error bound.
- The ratio of frames that have all joints within a certain distance to ground truth annotation
Proposed error metrics
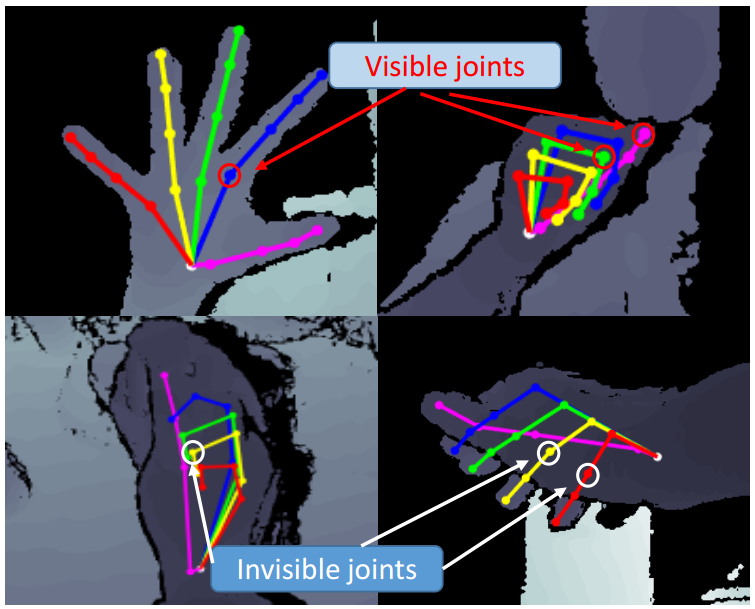
- Visibility: Hand pose often present occlusions, e.g., self occlusion and occlusion from objects. When occlusion happens, especially in the settings of egocentric view and hand-object interaction, measuring only the quality of the visible joints can be of interest.
- Hand pose rarity (frequency): Certain hand poses (e.g., open palm) appear more frequently than others (e.g., extending the ring finger and bent all other fingers). We propose a weighted error metric by taking into account the pose frequency in the testing data. By clustering the testing poses into groups, we give each hand pose a weight inversely proportional the size of the cluster it belongs to.
Dataset download
Fill this form to request access to HANDS 2017 challenge data.
If you are interested on the full BigHand2.2M dataset, fill this other form to request access.
To download the dataset, please send us an e-mail (hands.iccv17@outlook.com) including contact details (title, full name, organization, and country) and the purpose for downloading the dataset. Important note for students and post-docs: we require your academic supervisor to write the e-mail in your behalf. By sending the e-mail you accept the following terms and conditions.
Terms and conditions
The download and use of the challenge dataset is released for academic research only and it is free to researchers from educational or research institutes for non-commercial purposes. When downloading the dataset you agree to (unless with expressed permission of ICVL lab): not redistribute, modificate, or commercial usage of this dataset in any way or form, either partially or entirely.
Results submission
Submissions will be automatically handled on CodaLab. Participants can upload their results and automatically obtain a score for their submission and the participants might choose whether submit the score to a public leaderboard (one leaderboard per task). The order on the leaderboard will follow the reported average joint error discussed above. The team that appears on the first position on the leaderboard (lowest error) on the day of the submission deadline (15th September 1st October) will be the challenge winner. If we have different winner team on each task, we will consider having two challenge winners (one for each task). Before announcing the winners and awarding the prizes during the workshop, we will verify that the teams followed the rules. Submission for the hand-object task will be released in the future.
How to prepare your submission
Submissions for each task will be treated independently on CodaLab. You can choose if you want to participate in all tasks or only in one, however you only need to register once on CodaLab. If you want to try significantly different approaches you can register multiple times (contact us justifying this, registering multiple times trying to circumvent the per-day submissions limit will lead to disqualification).
- Generate a file containing the results of your algorithm in a .txt format and name it ‘result.txt’. Your submission file must look like this for frame-based task and like this for tracking task. The format is the same as in the provided annotations discussed above.
- Compress your .txt file in .zip format. Make sure not extra directories are created within the zip. For instance, try using something like:
zip -j result.txt.zip result.txt. The -j flag will not create extra directories within the zip. If you choose to participate in both tasks, you will have to generate two .zip files.
Important notes on format to avoid errors while submitting:
- Use tab character (\t) to separate items and a line jump to separate frames (\n).
- Lines follow numerical order of the provided testing images. In the case of the tracking task, where there are multiple sequences, follow numerical order first for sequence and then for frame as in the example.
- You need submit your results for all images in the testing set. This means that your result.txt file must have exactly 295510 lines for the frame-based task, exactly 294006 lines for the tracking task, and exactly 2965 for the hand-object tracj. Not following this will lead to an error in the submission.
How to submit your results
- Register on the CodaLab website for the ‘frame’ and ‘tracking’ tasks or for the Hand-Object task (go to the ‘Participate’ tab and follow the registration process). Please, use the same e-mail as you did for requesting the dataset. If this is not possible (eg your supervisor e-mailed us on your behalf), send us an e-mail mentioning this and cc’ing the address that requested the dataset.
- Go to your Account settings > Competition settings and choose a ‘Team name’. The team name can be chosen to preserve anonymity.
- Go to the Participate tab > Submit/View Results
- Choose the task to submit results (Frame/Tracking). Click the button ‘Submit’ and upload your generated .zip file. Here you can monitor the process of your submission. The submission won’t be complete until the tab STATUS is set to Finished. If you click the button ‘+’ you can access details of your submission such as your results and the output log (if your submission fails due to an error in the format, this will be useful). You may find this webpage useful.
Notes:
- You can submit results up to 5 times per day until the submission deadline (
15th September1st October). - The system currently outputs only three scores (see above for more details). This will remain unchanged during the challenge period, however submissions will be analyzed in a rigorous way for dissemination of results (as indicated in the related document). The scores measured are:
- AVG: average joint error (in mm). This will be the score used to decide the challenge winner.
- SEEN: average joint error over ‘seen’ subjects.
- UNSEEN: average joint error over ‘unseen’ subjects.
- The submission will fail if you don’t follow exactly the instructions above. If you are absolutely sure that you followed the instructions and your submission still fails, please send us an e-mail and we will have a look at your submission.
- It takes around 2 minutes to process one submission, although this depends on how busy are the CodaLab machines (and we can’t do anything about it).
- For final ranking and dissemination of results, we will only consider the latest submission by each team at the time that the challenge submission closes. It is responsibility of each team to make sure their latest submission is also their best.
Dissemination of results
We will present an analysis of challenge results in the workshop and prizes will be awarded to the top performant methods. We plan to publish a paper analything the results after the workshop, please check the participation rules for this.
Update: The CVPR 2018 paper is available here.
Organizers and contact
The challange is organized by Shanxin Yuan, Qi Ye, Guillermo Garcia-Hernando, and Tae-Kyun Kim (Imperial College London).
Feel free to drop us an e-mail if you have any further questions.
Related publications
If this challenge or dataset helps you in your research, please consider citing the following references:
[1] S. Yuan, Q. Ye, G. Garcia-Hernando, T.-K. Kim. The 2017 Hands in the Million Challenge on 3D Hand Pose Estimation. arXiv:1707.02237.
[2] S. Yuan, Q. Ye, B. Stenger, S. Jain, T.-K. Kim. BigHand2. 2M Benchmark: Hand Pose Dataset and State of the Art Analysis. CVPR 2017.
[3] G. Garcia-Hernando, S. Yuan, S. Baek, T.-K. Kim. First-Person Hand Action Benchmark with RGB-D Videos and 3D Hand Pose Annotations. CVPR 2018.
[4] S. Yuan, G. Garcia-Hernando, B. Stenger, et al. Depth-Based 3D Hand Pose Estimation: From Current Achievements to Future Goals. CVPR 2018.
Last update: 19/10/2018